Ollama是一个开源的大型语言模型服务,可以非常方便地部署最新版本的GPT模型并通过接口使用。支持热加载模型文件,无需重新启动即可切换不同的模型。简单来说Ollama是“一个允许你在本地机器上运行开源大型语言模型 (LLM) 的工具”。

Ollama有哪些优势呢?
- 提供类似OpenAI的简单内容生成接口,极易上手使用
- 类似ChatGPT的的聊天界面,无需开发直接与模型聊天
- 支持热切换模型,灵活多变
对设备配置有什么基本要求呢?
一说起大模型大家就想到了 GPU 和超贵的显卡,不过现在已经进化到可以在台式机或者笔记本电脑上本地运行。例如:8 GB 可用 RAM 可用运行 2B(20 亿参数) 的模型,16 GB 来运行 7B(70 亿参数) 型号,32 GB 来运行 13B(130 亿参数) 型号。下载模型文件时你留意一下模型的参数量级。
要在本地跑大语言模型,首先需要安装 Ollama,然后用 Ollama 命令安装模型文件,最后通过命令行或者 Raycast Ollama UI 插件来运行即可。
1、下载安装 https://ollama.com/ 支持 Mac 和 Windows
2、运行 Ollama,它将在后台常驻以便响应你的请求,终端中运行ollama -v判断一下是否安装成功
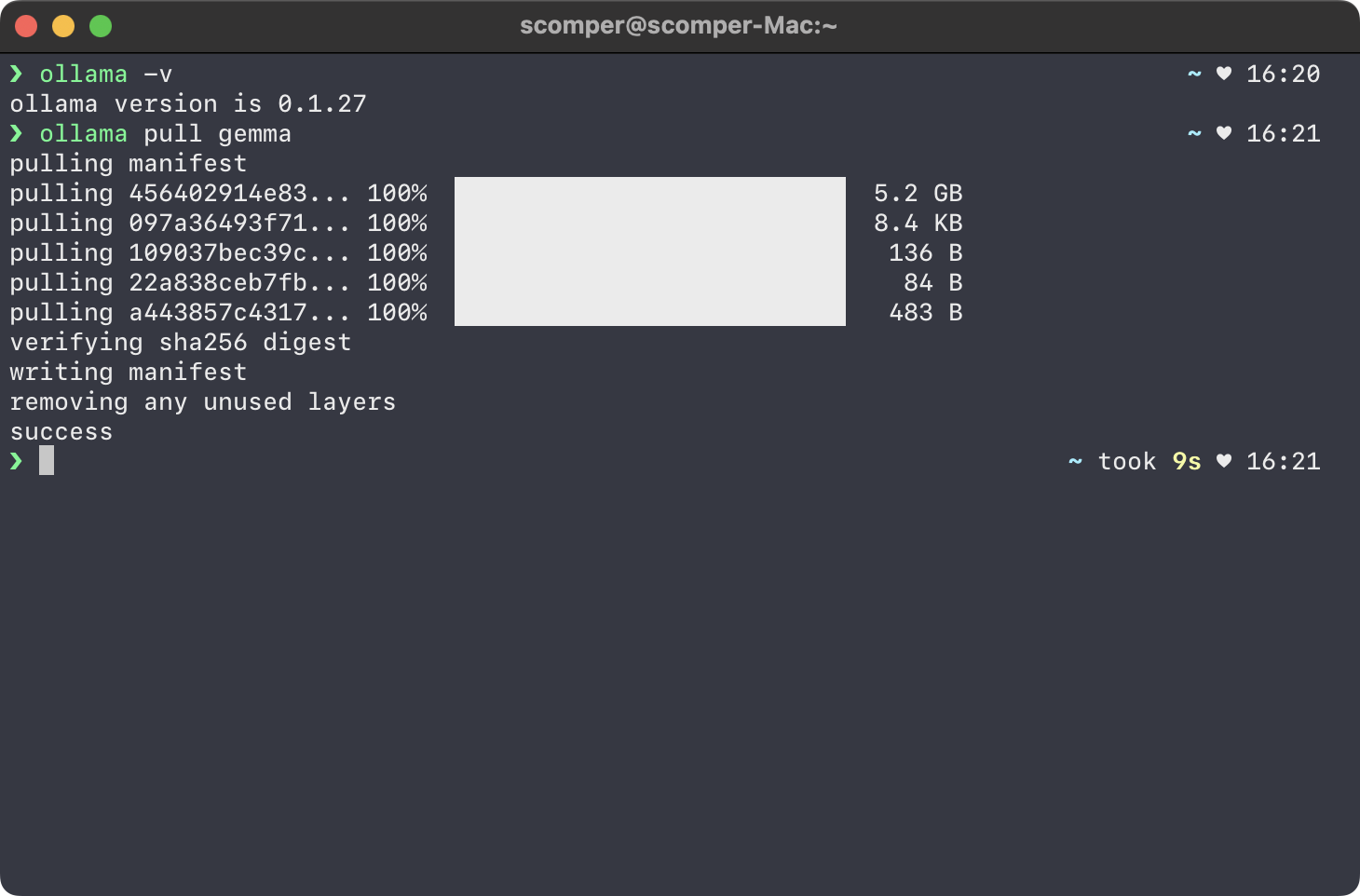
3、下载模型 ollama pull gemma ollama pull 语句就是下载指定的模型,这里指定下载 gemma 模型文件。具体的模型文件列表可以访问 https://ollama.com/library 查看,模型文件都比较大,建议针对自己的内存大小下载对应的版本
中文语境 gemma 和 llama2-chinese 模型效果都还不错。
模型下载完成后用 ollama list 命令可以查看一下下载好的模型文件。
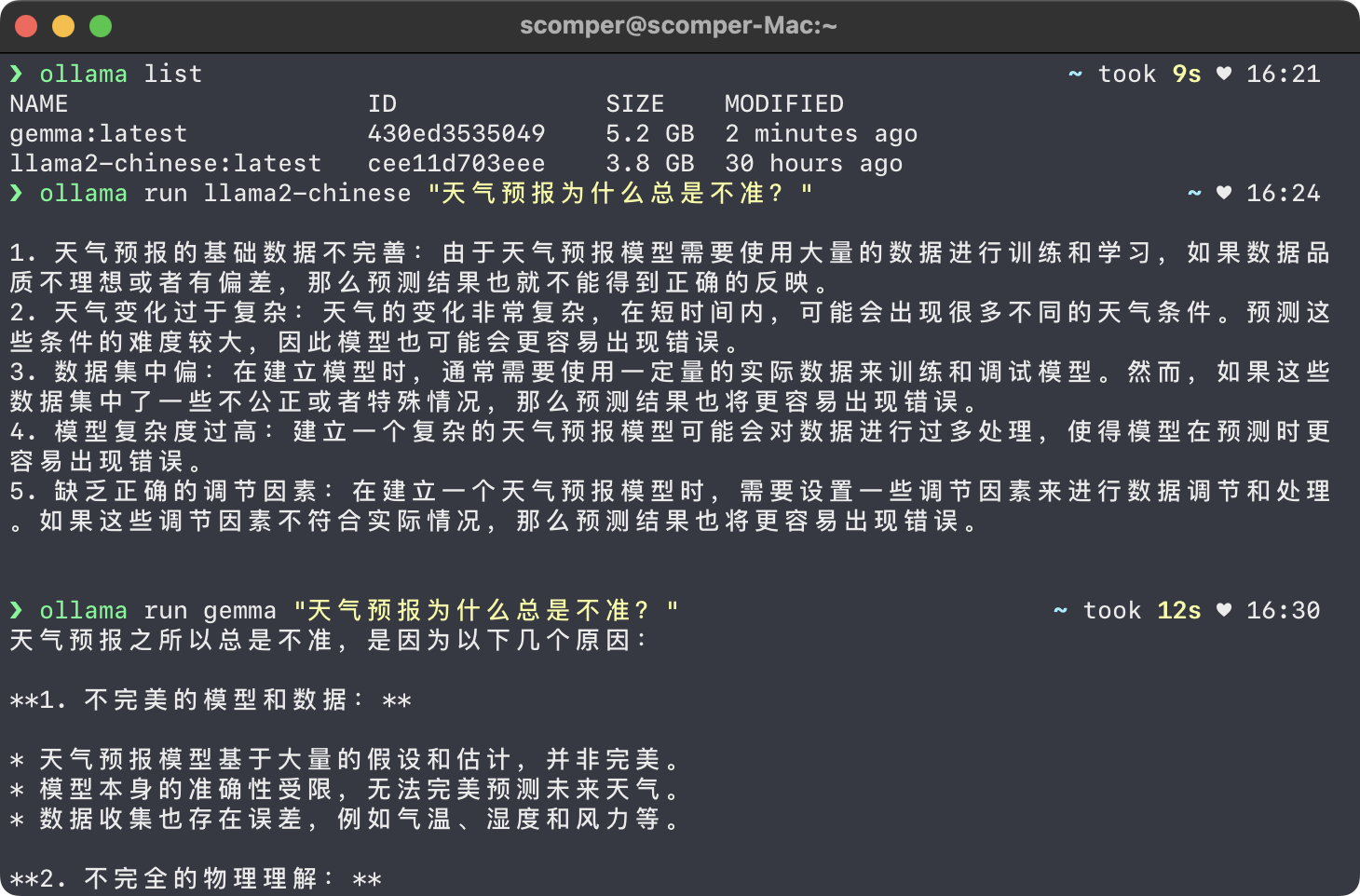
而且通过命令行的方式 ollama run gemma “问题描述” 已经可以向语音模型提问了,例如:
ollama run gemma "天气预报为什么总是不准?"
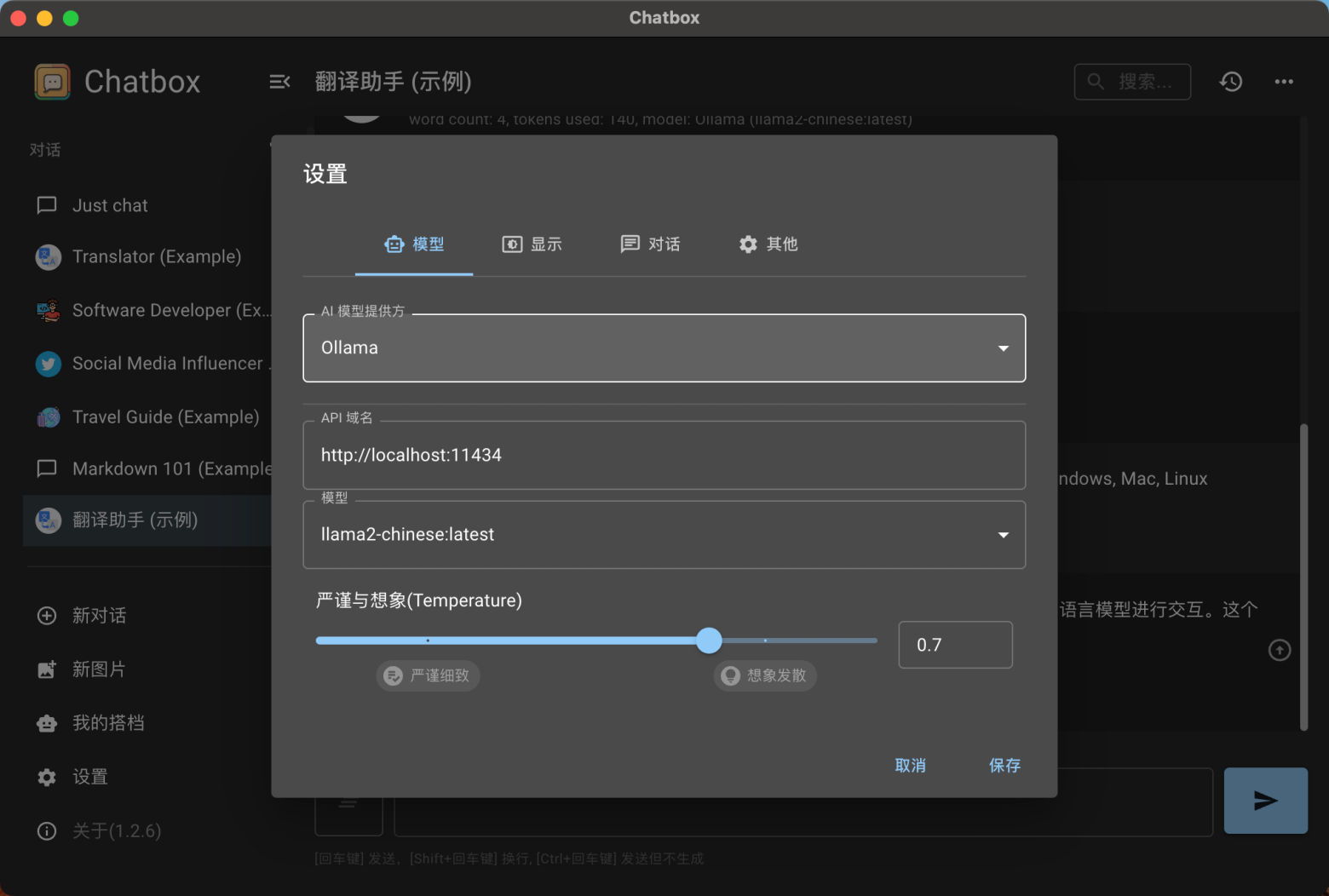
当然优雅一点的方式是安装 Chatbox 客户端,Chatbox支持多款全球最先进的AI大模型服务,支持Windows、Mac和Linux。也是目前不多的支持 Ollama 的客户端。配置很简单,只要在设置中选择 AI 模型提供方为 Ollama 即可,默认的 API 域名是本地 http://localhost:11434。
或者安装一个第三方的客户端 Ollamac,如果有安装 Raycast,增加一个Raycast Ollama 插件就能交互,个人觉得插件的方式最方便。

开发人员还可以通过 API 方式来调用,更多 API 参数查阅 GitHub 文档 https://github.com/ollama/ollama/blob/main/docs/api.md
curl http://localhost:11434/api/chat -d '{
"model": "mistral",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'最后推荐几个官方模型库里对中文支持相对较好或比较有趣的模型:
- Google 推出新一代开放 AI 模型 Gemma,这是一个轻量级的模型,比肩 Meta 的Llama 2 模型。
- DeepSeek 系列,深度求索团队推出,包括针对代码训练的 DeepSeek-Coder 和 通用的 DespSeek-LLM;
- Yi 系列,零一万物团队推出,有支持 20 万上下文窗口的版本可选;
PS:如果你有多台电脑,模型文件不用重复下载,直接将 ~/.ollama/models/ 模型文件夹中的所有内容 Copy 到另一台电脑即可。